Blog moving to https://ryanwomack.com/blog
I am shifting my blog activity to my own platform at
This has been the plan for a while, but I have finally started to post more actively there, so it is time to announce it!
As is my practice, I will remove posts that are more than 10 years old, so this site will gradually fade away.
Unofficial and informal tips for job applicants
Having been involved in several hiring committees over recent years, it is sometimes a bit frustrating to not be able to give advice to applicants. We cannot do that in individual cases as a matter of HR policy. The decision-making process is confidential. But I hope that by offering some general observations I have made after reviewing many applications, that this might be of help to future seekers. We are, after all, trying to find the person who will provide the best job performance, not perform the best in the application process. But since we only have the application to judge the candidate by, learning to perform well in the application is essential. I sincerely wish that every candidate would present their best during the application process. On to specifics…
The Library Work Environment
Librarians have a service ethic. We are (mostly) in this profession to help: to help organize information, to help others find information, to help others use information. But information can be complex. So we are usually looking for a combination of both specialized technical expertise and the willingness and ability to explain, to teach, to help.
If you are already a working professional librarian, this paragraph probably does not apply to you, but others read on. We like people who like to read, to study, to use books. However, that is no longer what most library work is about. Even if you have used libraries extensively in the past, you probably do not know the particular requirements of the position we are advertising for. Avoid making sweeping statements about how you will enjoy the work, or will improve the Libraries. You just don’t know how that will play out.
The Cover Letter
In many of our positions, we are looking for people with advanced technical skills that they can put to use with us. It is common to find applications that list these skills on the resume, but that add little else. That kind of application might be fine in your discipline, especially for in-demand skills like newer programming languages. But (as mentioned above), we are seeking skills+service. Your cover letter is the place for you to demonstrate your communication skills and convey any evidence of your helpfulness, desire and experience teaching, and flexibility in learning and adapting to job requirements.
This is basic, but many still don’t do it. You should read the position description, and your cover letter should address how you meet each of the requirements. If you do not, you will probably be passed over for an applicant who has covered all of those bases. You may be capable of doing the job, but if the cover letter doesn’t explain how, we cannot fill in the blanks for you.
Also, it is nice if you think the job will help you develop your skills, be a good progression for your career, and so on. But you should limit discussion of that to just a sentence or two. The reason the job has been posted is that the Libraries need to get some work done. So 90% of your effort should be convincing us that you are the best person to do that work, not that the work is the best for you.
The Interview
If you are selected for an interview, it means you are on a very short list of people we are seriously considering for the position, usually just two or three people. So congratulations!
Recognize that it is often not possible to “win” the interview over other candidates just by trying harder or saying things differently. Often it is the fundamental match of skills and experience to the position that determines the choice. A great candidate may just need more experience, or may be developing in a different direction than the Libraries’ current needs. Don’t sweat it if you are not the match today. Career development is a process, and not a linear one.
Do be a good sport about every step of the process. Mostly, everyone involved on the employer’s side is just trying to do their jobs well. All of academia is a small world, with plenty of chances to meet people again in different contexts. So be courteous and polite because you never know. The vast majority of you don’t need this reminder, but unfortunately there are a few who do.
During the interview, you want to continue what you started in your cover letter. Explain how you qualify for the position, and what strengths you have that make you the best candidate. Talk about both how you are knowledgeable and how you will be helpful. Show that you have good communication skills in person.
You should ask questions. It is often difficult for those with less experience and less practice interviewing to know what to ask, but you should prepare some questions beforehand. Questions show that you are seriously thinking about the work involved, and will be an active and engaged worker. At least you can ask what the employers expect to accomplish by hiring someone.
Listen to and respond directly to the questions asked of you. If there are multiple interviewers, which is typical, try to give attention to each person at least part of the time. They are there for a reason, and they will all have a voice in the final decision. Do not assume you know who is in charge, or the most important person in the room, and direct your attention only to them. You might not be right!
You may have many qualifications, but it is hard to list them all in a short interview. So think about the most powerful examples you can talk about in advance and have them ready. If you haven’t thought yet about how to describe your qualifications, definitely take the time before the interview. Don’t spend your limited time by talking about things you know are not as important, or where you may not have made much of a contribution, even if they are very interesting to you.
If you are new to the academic work environment (as compared to the classroom), you might be surprised by just how dry and formal it can be, especially in official settings like a job interview. So save raising any personal or highly opinionated topics for after you are hired. If there are personal issues that affect things like your schedule availability, you can raise those in a neutral way. It is fine to leave those discussions until after you have been selected too.
Good luck with your job search!
R Workshops, a tidyverse approach, Fall 2019
A bit late posting about this, but my R workshops start tomorrow. This year I am revising my materials to reflect a tidyverse-centric approach. I am not a tidyverse convert or even a particular fan, but I would like to teach this popular and coherent ecosystem as an entry-point to R. I hope it does not discourage learning the entire diversity of the R space.
These workshops are open to all without registration.
Bring your own laptop to these sessions to get the most out of them!
Later in the semester, there are plans to repeat these as webinars (schedule to come in late September).
R for data analysis: a tidyverse approach 
- Wednesday, September 25 – 12:00-1:20 pm, LSM Conference Room
- Thursday, October 3– 2:50-4:10 pm, Alexander Library Room 415
The session introduces the R statistical software environment and basic methods of data analysis, and also introduces the “tidyverse”. While R is much more than the “tidyverse”, the development of the “tidyverse” set of packages, led by RStudio, has provided a powerful and connected toolkit to get started with using R. Note that graphics and data manipulation are covered in subsequent sessions.
R graphics with ggplot2 
- Wednesday, October 2 – 12:00-1:20 pm, LSM Conference Room
- Thursday, October 10– 2:50-4:10 pm, Alexander Library Room 415
The ggplot2 package from the tidyverse provides extensive and flexible graphical capabilities within a consistent framework. This session introduces the main features of ggplot2. Some prior familiarity with R is assumed (packages, structure, syntax), but the presentation can be followed without this background.
R data wrangling with dplyr, tidyr, readr and more 
- Wednesday, October 9 – 12:00-1:20 pm, LSM Conference Room
- Thursday, October 24 – 2:50-4:10 pm, Alexander Library Room 415
Some of the most powerful features of the tidyverse relate to its abilities to import, filter, and otherwise manipulate data. This session reviews major packages within the tidyverse that relate to the essential data handling steps require before (and during) data analysis.
R for interactivity: an introduction to Shiny 
- Wednesday, October 23 – 12:00-1:20 pm, LSM Conference Room
- Thursday, October 31 – 2:50-4:10 pm, Alexander Library Room 415
Shiny is an R package that enables the creation of interactive websites for data visualization. This session provides a brief overview of the Shiny framework, and how to edit and publish Shiny sites in RStudio (with shinyapps.io). Familiarity with R/RStudio is assumed.
R for reproducible scientific documents: knitr, rmarkdown, and beyond 
- Wednesday, October 30 – 12:00-1:20 pm, LSM Conference Room
- Thursday, November 7 – 2:50-4:10 pm, Alexander Library Room 415
The RStudio environment enables the easy creation of documents in various formats (HTML, DOC, PDF) using Rmarkdown, while knitr allows the incorporation of executable R code to produce the tables and figures in those documents. This session introduces these concepts and other packages and practices supporting reproducibility with the R environment.
October Python Workshops
The New Brunswick Libraries’ Quantiative Data Analytics Graduate Specialist, Hang Miao, will be offering a three-part series of Python workshops in October, starting Friday October 5.
Note: additional more advanced workshops for November will be announced later in October.
☞ RSVP for the Python workshops.
Workshops are offered in either Alexander Library or LSM (with identical content). Participants in LSM-based workshops must bring their own laptops. At Alexander, you can either bring your own laptop, or use the desktops in the lab.
Python Basics and Data Exploration
October 5, 1-3 pm, Alexander Library Room 413
October 10, 3:30-5:30 pm, Library of Science and Medicine Electronic Classroom (3rd floor)
This workshop will be an accelerated introduction to fundamental concepts such as variable assignment, data types, basic calculations, working with strings and lists, control structures (e.g. for-loops), functions. We will also start working with pandas, a popular data science library in Python, to explore a dataset on foodborne outbreaks reported to the CDC.
Data Manipulation and Analysis
October 12, 1-3 pm, Alexander Library Room 413
October 17, 3:30-5:30 pm, Library of Science and Medicine Conference Room (1st Floor)
In this workshop, we will dive into the world of arrays and data frames using the NumPy and pandas libraries. We’ll cover data cleaning and pre-processing, joining and merging, group operations, and more. If you work with tabular data, this workshop is for you!
Data Visualization and Machine Learning
October 19, 1-3 pm, Alexander Library Room 413
October 24, 3:30-5:30 pm, Library of Science and Medicine Conference Room (1st floor)
Interested in finding patterns and predicting unknown attribute values in your data? Join us for an overview of machine learning techniques implemented using the scikit-learn library. We’ll also learn how to do data visualization with matplotlib, a popular plotting library in Python.
Open Follow-up Session on Python
October 26, 1-3 pm, Alexander Library Room 413
October 31 3:30-5:30 pm, Library of Science and Medicine Electronic Classroom (3rd floor)
This open session allows participants to bring their questions or issues from previous sessions to practice and further develop skills.
Statistical Software and Data Workshops, Fall 2018
New Brunswick Libraries Data Workshop Series
Fall 2018
This Fall, Ryan Womack, Data Librarian, will offer a series of workshops on statistical software and data visualization as part of New Brunswick Libraries Data Management Services. A detailed calendar and descriptions of each workshop are below. The workshop on reproducible research is moving online to YouTube – stay tuned for an upcoming blog post and announcement on its availability. We also anticipate offering additional workshops through the Graduate Specialist program. That announcement will be coming in September.
This semester each workshop topic will be repeated twice in person, once at the Library of Science and Medicine on Busch Campus, and once at Alexander Library on College Ave. These sessions will be identical except for location. Sessions will run approximately 3 hours. Workshops in parts will divide the time in thirds. For example, the first SPSS, Stata, and SAS workshop (running from 1:10-4:10 pm) would start with SPSS at 1:10 pm, Stata at 2:10 pm, and SAS at 3:10 pm. You are free to come only to those segments that interest you. There is no need to register, just come! A
Logistics
Location: The Library of Science and Medicine (LSM on Busch) workshops will be held in the Conference Room on the 1st floor of LSM on Mondays from 12 to 3 pm. The Alexander Library (College Ave) workshops will be held in room 413 of the Scholarly Communication Center (4th floor of Alexander Library) from on Tuesdays from 1:10 to 4:10 pm.
For both locations, you are encouraged to bring your own laptop to work in your native environment. Alternatively, at Alexander Library, you can use a library desktop computer instead of your own laptop. At LSM, we will have laptops available to borrow for the session if you don’t bring your own. Room capacity is 25 in both locations, first come, first served.
If you can’t make the workshops, or would like a preview or refresher, screencast versions of many of the presentations are already available at https://libguides.rutgers.edu/data and https://youtube.com/librarianwomack. Additional screencasts are continually being added to this series. Note that the “special topics” [Time Series, Survival Analysis, and Big Data] are no longer offered in person, but are available via screencast.
Calendar of workshops
| Wednesday (LSM)
12 noon – 3 pm |
Thursday (Alexander)
1:10 pm -4:10 pm |
|
| October 3 | Introduction to SPSS, Stata, and SAS | September 13 |
| October 10 | Introduction to R | September 20 |
| October 17 | Data Visualization in R | September 27 |
Description of Workshops:
§ Introduction to SPSS, Stata, and SAS (September 13 or October 3) provides overviews of these three popular commercial statistical software programs, covering the basics of navigation, loading data, graphics, and elementary descriptive statistics and regression using a sample dataset. If you are already using these packages with some degree of success, you may find these sessions too basic for you.
- SPSS is widely used statistical software with strengths in survey analysis and other social science disciplines. Copies of the workshop materials, a screencast, and additional SPSS resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208425. SPSS is made available by OIRT at a discounted academic rate, currently $100/academic year. Find it at software.rutgers.edu. SPSS is also available in campus computer labs and via the Apps server (see below).
- Stata is flexible and allows relatively easy access to programming features. It is popular in economics among other areas. Copies of the workshop materials, a screencast, and additional Stata resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208427. Stata is made available by OIRT via campus license with no additional charge to install for Rutgers users. Find it at software.rutgers.edu.
- SAS is a powerful and long-standing system that handles large data sets well, and is popular in the pharmaceutical industry and health sciences, among other applications. Copies of the workshop materials, a screencast, and additional SAS resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208423. SAS is made available by OIRT at a discounted academic rate, currently $100/academic year. Find it at software.rutgers.edu. SAS is also available in campus computer labs, online via the SAS University Edition cloud service, and via the Apps server (see below).
Note: Accessing software via apps.rutgers.edu
SPSS, SAS, Stata, and R are available for remote access on apps.rutgers.edu. apps.rutgers.edu does not require any software installation, but you must activate the service first at netid.rutgers.edu.
§ Introduction to R (September 20 or October 10) – This session provides a three-part orientation to the R programming environment. R is freely available, open source statistical software that has been widely adopted in the research community. Due to its open nature, thousands of additional packages have been created by contributors to implement the latest statistical techniques, making R a very powerful tool. No prior knowledge is assumed. The three parts cover:
- Statistical Techniques: getting around in R, descriptive statistics, regression, significance tests, working with packages
- Graphics: comparison of graphing techniques in base R, lattice, and ggplot2 packages
- Data Manipulation: data import and transformation, additional methods for working with large data sets, also dplyr and other packages from the tidyverse useful for manipulation.
Additional R resources, including handouts, scripts, and screencast versions of the workshops, can be found here: http://libguides.rutgers.edu/data_R
R is freely downloadable from http://r-project.org
§ Data Visualization in R (September 27 or October 17) discusses principles for effective data visualization, and demonstrates techniques for implementing these using R. Some prior familiarity with R is assumed (packages, structure, syntax), but the presentation can be followed without this background. The three parts are:
- Principles & Use in lattice and ggplot2: discusses classic principles of data visualization (Tufte, Cleveland) and illustrates them with the use of the lattice and ggplot2 packages. Some of the material here overlaps with Intro to R, pt 2, but at a higher level.
- Miscellany of Methods: illustrates a wide range of specific graphics for different contexts
- 3-D, Interactive, and Big Data: presentation of 3-D data, interactive exploration data, and techniques for large datasets. Relevant packages such as shiny and tessera are explored.
Additional R resources can be found here: http://libguides.rutgers.edu/data_R
R is freely downloadable from http://r-project.org
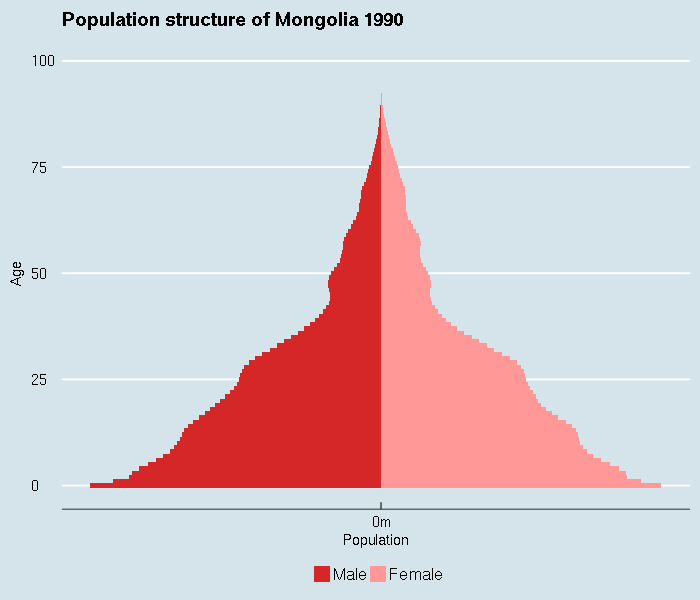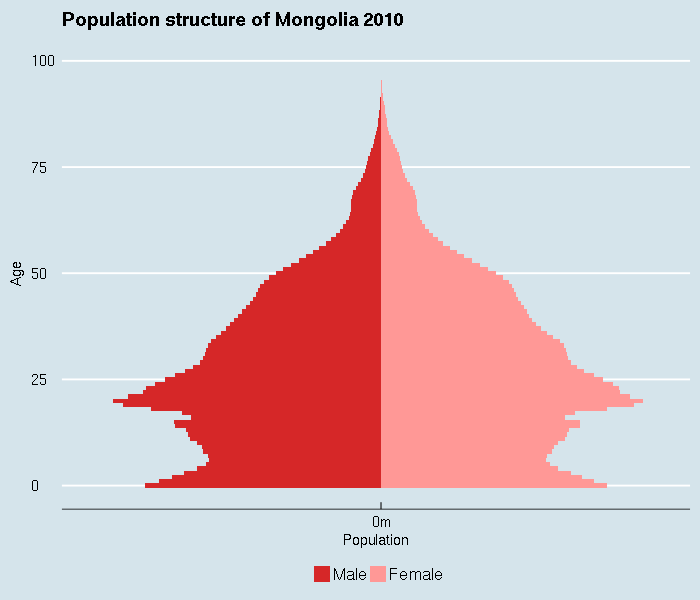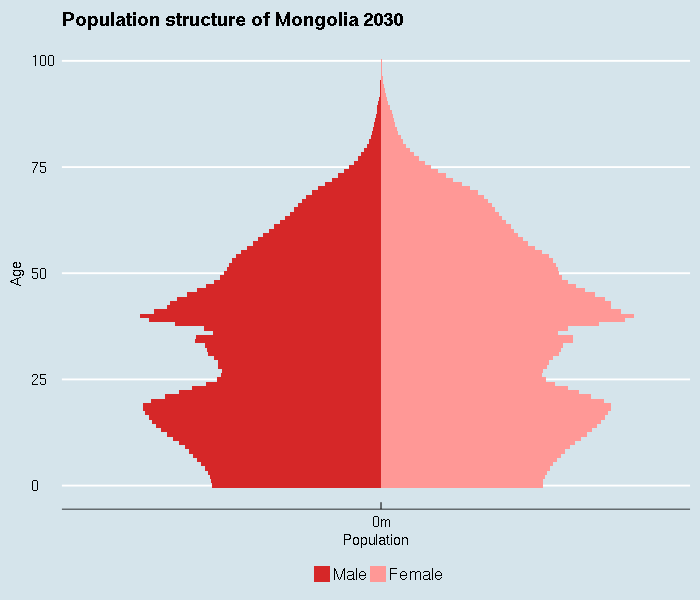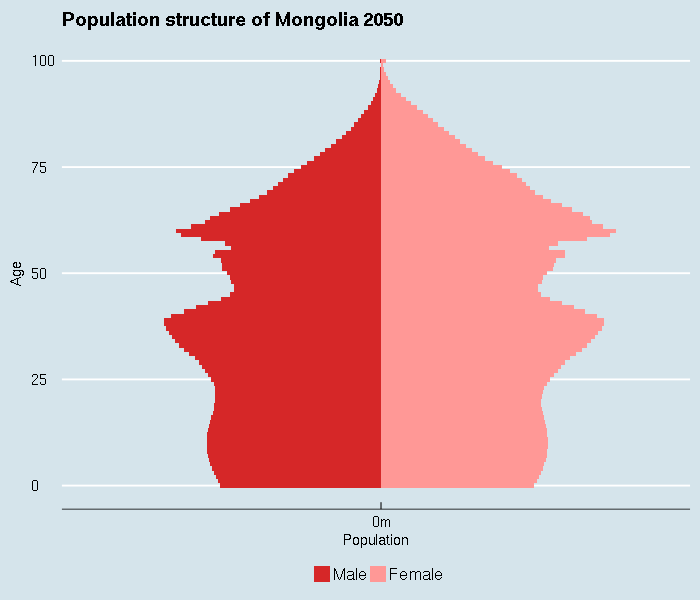
Note that the following special topics are no longer covered by in-person workshops, but are available via screencast.
- Reproducible Research – [Coming Soon] how to create data, code, and publications in open, reusable formats and maximize the impact and validity of your research.
- Time Series in R: review of commands and techniques for basic time series analysis in R. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hOA2q0sfDNKBH9WIlLxXkbn and scripts at http://libguides.rutgers.edu/data_R
- Survival Analysis in R: review of commands and techniques for basic survival analysis in R. Scripts at http://libguides.rutgers.edu/data_R. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hOON9isnuVYIL8dNwkvwqr9.
- Big Data in Brief: an introduction to some of the techniques and software environments used to work with big data, with pointers to resources for further learning at http://libguides.rutgers.edu/bigdata. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hMNhIdrvz1F5-JHIWi1qdX1
Mongolian Multivariate Statistics (at the Mongolian University of Life Sciences)
I was delighted to be invited to return to Mongolia again for a more in-depth visit to the Mongolian University of Life Sciences [Хөдөө Аж Ахуйн Их Сургууль]. I was honored by the invitation from the Dean of the School of Economics and Business [Эдийн засаг бизнесийн сургууль], B. Baasansukh, and P. Munkhtuya, Chair of the Department of Economic Statistics and Mathematical Modeling, to come and teach a one week Short Course on Applied Multivariate Statistical Methods with R [Олон хэмжээст статистикийн богино хэмжээний сургалт R программ дээр]. This post is a brief summary of my trip.


I got to Ulaanbaatar on my first ever flight on MIAT Mongolian Airlines, which was quite comfortable.
On Monday, February 26, we jumped right into work. The material for the short course was adapted from the book and associated R code by Brian Everitt and Torsten Hothorn, An Introduction to Applied Multivariate Statistical Analysis with R, Springer, 2011. The eight chapters of the book were covered in four days. Topics covered were the following:
- R environment, setup, basics
- Multivariate Analysis – what is it?
- Data Exploration and Visualization
- Principal Components
- Multidimensional Scaling
- Exploratory Factor Analysis
- Confirmatory Factor Analysis
- Structural Equation Modeling
- Cluster Analysis
- Repeated Measures
The Everitt and Hothorn text was particularly useful for its compact treatment of complex topics, and the self-contained nature of the included R code demo modules.
There were a total of 31 participants attending, although course and meeting conflicts prevented some from coming every day. The MULS School of Economics and Business had 20 participants, with the remaining attendees coming from the Division of Science and Research, the School of Agroecology, the School of Veterinary Medicine, and the School of Engineering and Technology. Outside of MULS, participants also came from the National Statistics Office of Mongolia and the Cabinet Secretariat of the Government of Mongolia.
All participants followed along by executing sample code on their own laptops. All presentation materials and code are available from https://github.com/ryandata/multivariate. Supplemental texts and files were made available using a portable PirateBox to distribute materials via local wireless network. See this post on how to set up a PirateBox.




The interaction was lively and particularly aided by assistance in translation from G. Bilguun, O. Amartuvshin, and T. Suvdmaa. I hope the participants enjoyed it as much as I did!




Putting our knowledge of R to immediate use, we used R to select a random sample of winners of swag provided by Rutgers’ Master of Business and Science program.



During the week, I also had the opportunity for several meetings to discuss future collaborations on projects to improve the academic and data infrastructure of MULS, which I believe will be the subject of future collaborations. The week also included some delicious food, including a hot pot dinner and khorkhog [хopxoг] and khuushuur [хуушууp].


On Thursday afternoon, I had the opportunity to address a group of undergraduate statistics majors on trends in data science and its intersection with statistics. I argued that the expansion in the power and availability of open source software and data has made it possible for anyone, from Mongolia or even the United States (where there are arguably more distractions) to study and master the tools and skills that underpin the most dynamic growth sectors for future jobs.
Finally on Friday, we wrapped up the course with some final discussion and the presentation of certificates to participants.
Mongolia is always a land of warm welcome and surprises. Thanks to my hosts at SEB-MULS for a fantastic trip, filled with learning. Thanks to D Music for inspiration as always. And thanks especially to P. Munkhtuya for leading all of the organizational efforts for my visit. I am looking forward to working together with MULS colleagues in the future! Маш их баярлалаа!



Statistical Software and Data Workshops, Spring 2018
New Brunswick Libraries Data Workshop Series
Spring 2018
This Spring, Ryan Womack, Data Librarian, will repeat the series of workshops on statistical software and data visualization as part of New Brunswick Libraries Data Management Services. A detailed calendar and descriptions of each workshop are below. The workshop on reproducible research is moving online to YouTube – stay tuned for an upcoming blog post and announcement on its availability.
This semester each workshop topic will be repeated twice, once at the Library of Science and Medicine on Busch Campus, and once at Alexander Library on College Ave. These sessions will be identical except for location. Sessions will run approximately 3 hours. Workshops in parts will divide the time in thirds. For example, the first SPSS, Stata, and SAS workshop (running from 12-3 pm) would start with SPSS at 12 pm, Stata at 1 pm, and SAS at 2 pm. You are free to come only to those segments that interest you. There is no need to register, just come!
Logistics
Location: The Library of Science and Medicine (LSM on Busch) workshops will be held in the Conference Room on the 1st floor of LSM on Mondays from 12 to 3 pm. The Alexander Library (College Ave) workshops will be held in room 413 of the Scholarly Communication Center (4th floor of Alexander Library) from on Tuesdays from 1:10 to 4:10 pm.
For both locations, you are encouraged to bring your own laptop to work in your native environment. Alternatively, at Alexander Library, you can use a library desktop computer instead of your own laptop. At LSM, we will have laptops available to borrow for the session if you don’t bring your own. Room capacity is 25 in both locations, first come, first served.
If you can’t make the workshops, or would like a preview or refresher, screencast versions of many of the presentations are already available at http://libguides.rutgers.edu/data and https://youtube.com/librarianwomack. Additional screencasts are continually being added to this series. Note that the “special topics” [Time Series, Survival Analysis, and Big Data] are no longer offered in person, but are available via screencast.
Calendar of workshops
| Monday (LSM)
12 noon – 3 pm |
Tuesday (Alexander)
1:10 pm -4:10 pm |
|
| January 29 | Introduction to SPSS, Stata, and SAS | January 30 |
| February 5 | Introduction to R | February 6 |
| February 12 | Data Visualization in R | February 13 |
Description of Workshops:
§ Introduction to SPSS, Stata, and SAS (January 29 or January 30) provides overviews of these three popular commercial statistical software programs, covering the basics of navigation, loading data, graphics, and elementary descriptive statistics and regression using a sample dataset. If you are already using these packages with some degree of success, you may find these sessions too basic for you.
- SPSS is widely used statistical software with strengths in survey analysis and other social science disciplines. Copies of the workshop materials, a screencast, and additional SPSS resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208425. SPSS is made available by OIRT at a discounted academic rate, currently $100/academic year. Find it at software.rutgers.edu. SPSS is also available in campus computer labs and via the Apps server (see below).
- Stata is flexible and allows relatively easy access to programming features. It is popular in economics among other areas. Copies of the workshop materials, a screencast, and additional Stata resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208427. Stata is made available by OIRT via campus license with no additional charge to install for Rutgers users. Find it at software.rutgers.edu.
- SAS is a powerful and long-standing system that handles large data sets well, and is popular in the pharmaceutical industry and health sciences, among other applications. Copies of the workshop materials, a screencast, and additional SAS resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208423. SAS is made available by OIRT at a discounted academic rate, currently $100/academic year. Find it at software.rutgers.edu. SAS is also available in campus computer labs, online via the SAS University Edition cloud service, and via the Apps server (see below).
Note: Accessing software via apps.rutgers.edu
SPSS, SAS, Stata, and R are available for remote access on apps.rutgers.edu. apps.rutgers.edu does not require any software installation, but you must activate the service first at netid.rutgers.edu.
§ Introduction to R (February 5 or February 6) – This session provides a three-part orientation to the R programming environment. R is freely available, open source statistical software that has been widely adopted in the research community. Due to its open nature, thousands of additional packages have been created by contributors to implement the latest statistical techniques, making R a very powerful tool. No prior knowledge is assumed. The three parts cover:
- Statistical Techniques: getting around in R, descriptive statistics, regression, significance tests, working with packages
- Graphics: comparison of graphing techniques in base R, lattice, and ggplot2 packages
- Data Manipulation: data import and transformation, additional methods for working with large data sets, also dplyr and other packages from the tidyverse useful for manipulation.
Additional R resources, including handouts, scripts, and screencast versions of the workshops, can be found here: http://libguides.rutgers.edu/data_R
R is freely downloadable from http://r-project.org
§ Data Visualization in R (February 12 or February 13) discusses principles for effective data visualization, and demonstrates techniques for implementing these using R. Some prior familiarity with R is assumed (packages, structure, syntax), but the presentation can be followed without this background. The three parts are:
- Principles & Use in lattice and ggplot2: discusses classic principles of data visualization (Tufte, Cleveland) and illustrates them with the use of the lattice and ggplot2 packages. Some of the material here overlaps with Intro to R, pt 2, but at a higher level.
- Miscellany of Methods: illustrates a wide range of specific graphics for different contexts
- 3-D, Interactive, and Big Data: presentation of 3-D data, interactive exploration data, and techniques for large datasets. Relevant packages such as shiny and tessera are explored.
Additional R resources can be found here: http://libguides.rutgers.edu/data_R
R is freely downloadable from http://r-project.org
Note that the following special topics are no longer covered by in-person workshops, but are available via screencast.
- Reproducible Research – [Coming Soon] how to create data, code, and publications in open, reusable formats and maximize the impact and validity of your research.
- Time Series in R: review of commands and techniques for basic time series analysis in R. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hOA2q0sfDNKBH9WIlLxXkbn and scripts at http://libguides.rutgers.edu/data_R
- Survival Analysis in R: review of commands and techniques for basic survival analysis in R. Scripts at http://libguides.rutgers.edu/data_R. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hOON9isnuVYIL8dNwkvwqr9.
- Big Data in Brief: an introduction to some of the techniques and software environments used to work with big data, with pointers to resources for further learning at http://libguides.rutgers.edu/bigdata. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hMNhIdrvz1F5-JHIWi1qdX1
Statistical Software and Data Workshops, Fall 2017
New Brunswick Libraries Data Workshop Series
Fall 2017
This Fall, Ryan Womack, Data Librarian, will offer a series of workshops on statistical software, data visualization, and reproducible research as part of New Brunswick Libraries Data Management Services. A detailed calendar and descriptions of each workshop are below. This semester each workshop topic will be repeated twice, once at the Library of Science and Medicine on Busch Campus, and once at Alexander Library on College Ave. These sessions will be identical except for location. Sessions will run approximately 3 hours. Workshops in parts will divide the time in thirds. For example, the first SPSS, Stata, and SAS workshop (running from 12-3 pm) would start with SPSS at 12 pm, Stata at 1 pm, and SAS at 2 pm. You are free to come only to those segments that interest you. There is no need to register, just come!
Logistics
Location: The Library of Science and Medicine (LSM on Busch) workshops will be held in the Conference Room on the 1st floor of LSM on Wednesdays from 12 to 3 pm. The Alexander Library (College Ave) workshops will be held in room 413 of the Scholarly Communication Center (4th floor of Alexander Library) from on Tuesdays from 1:10 to 4:10 pm.
For both locations, you are encouraged to bring your own laptop to work in your native environment. Alternatively, at Alexander Library, you can use a library desktop computer instead of your own laptop. At LSM, we will have laptops available to borrow for the session if you don’t bring your own. Room capacity is 25 in both locations, first come, first served.
If you can’t make the workshops, or would like a preview or refresher, screencast versions of many of the presentations are already available at http://libguides.rutgers.edu/data and https://youtube.com/librarianwomack. Additional screencasts are continually being added to this series. Note that the “special topics” [Time Series, Survival Analysis, and Big Data] are no longer offered in person, but are available via screencast.
Calendar of workshops
| Tuesday (Alexander)
1:10 pm -4:10 pm |
Wednesday (LSM)
12 noon – 3 pm |
|
| September 12 | Introduction to SPSS, Stata, and SAS | September 13 |
| September 19 | Introduction to R | September 20 |
| September 26 | Data Visualization in R | September 27 |
| October 3 | Reproducible Research | October 18 |
Description of Workshops:
§ Introduction to SPSS, Stata, and SAS (September 12 or September 13) provides overviews of these three popular commercial statistical software programs, covering the basics of navigation, loading data, graphics, and elementary descriptive statistics and regression using a sample dataset. If you are already using these packages with some degree of success, you may find these sessions too basic for you.
- SPSS is widely used statistical software with strengths in survey analysis and other social science disciplines. Copies of the workshop materials, a screencast, and additional SPSS resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208425. SPSS is made available by OIRT at a discounted academic rate, currently $100/academic year. Find it at software.rutgers.edu. SPSS is also available in campus computer labs and via the Apps server (see below).
- Stata is flexible and allows relatively easy access to programming features. It is popular in economics among other areas. Copies of the workshop materials, a screencast, and additional Stata resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208427. Stata is made available by OIRT via campus license with no additional charge to install for Rutgers users. Find it at software.rutgers.edu.
- SAS is a powerful and long-standing system that handles large data sets well, and is popular in the pharmaceutical industry and health sciences, among other applications. Copies of the workshop materials, a screencast, and additional SAS resources can be found here: http://libguides.rutgers.edu/content.php?pid=115296&sid=1208423. SAS is made available by OIRT at a discounted academic rate, currently $100/academic year. Find it at software.rutgers.edu. SAS is also available in campus computer labs, online via the SAS University Edition cloud service, and via the Apps server (see below).
Note: Accessing software via apps.rutgers.edu
SPSS, SAS, Stata, and R are available for remote access on apps.rutgers.edu. apps.rutgers.edu does not require any software installation, but you must activate the service first at netid.rutgers.edu.
§ Introduction to R (September 19 or September 20) – This session provides a three-part orientation to the R programming environment. R is freely available, open source statistical software that has been widely adopted in the research community. Due to its open nature, thousands of additional packages have been created by contributors to implement the latest statistical techniques, making R a very powerful tool. No prior knowledge is assumed. The three parts cover:
- Statistical Techniques: getting around in R, descriptive statistics, regression, significance tests, working with packages
- Graphics: comparison of graphing techniques in base R, lattice, and ggplot2 packages
- Data Manipulation: data import and transformation, additional methods for working with large data sets, also dplyr and other packages from the tidyverse useful for manipulation.
Additional R resources, including handouts, scripts, and screencast versions of the workshops, can be found here: http://libguides.rutgers.edu/data_R
R is freely downloadable from http://r-project.org
§ Data Visualization in R (September 26 or September 27) discusses principles for effective data visualization, and demonstrates techniques for implementing these using R. Some prior familiarity with R is assumed (packages, structure, syntax), but the presentation can be followed without this background. The three parts are:
- Principles & Use in lattice and ggplot2: discusses classic principles of data visualization (Tufte, Cleveland) and illustrates them with the use of the lattice and ggplot2 packages. Some of the material here overlaps with Intro to R, pt 2, but at a higher level.
- Miscellany of Methods: illustrates a wide range of specific graphics for different contexts
- 3-D, Interactive, and Big Data: presentation of 3-D data, interactive exploration data, and techniques for large datasets. Relevant packages such as shiny and tessera are explored.
Additional R resources can be found here: http://libguides.rutgers.edu/data_R
R is freely downloadable from http://r-project.org
§ Reproducible Research (October 3 or October 18) covers
- Reproducible research describes the growing movement to make the products of research accessible and usable by others in order to verify, replicate, and extend research findings. This session reviews how to plan research, to create publications, code, and data in open, reusable formats, and maximize the impact of shared research findings. Examples in LaTeX and Rmarkdown are discussed, along with platforms for reusability such as the Open Science Foundation.
Additional resources on reproducible research and data management, including presentation slides, can be found here: http://libguides.rutgers.edu/datamanagement
§ Special Topics
Note that the following special topics are no longer covered by in-person workshops, but are available via screencast.
- Time Series in R: review of commands and techniques for basic time series analysis in R. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hOA2q0sfDNKBH9WIlLxXkbn and scripts at http://libguides.rutgers.edu/data_R
- Survival Analysis in R: review of commands and techniques for basic survival analysis in R. Scripts at http://libguides.rutgers.edu/data_R. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hOON9isnuVYIL8dNwkvwqr9.
- Big Data in Brief: an introduction to some of the techniques and software environments used to work with big data, with pointers to resources for further learning at http://libguides.rutgers.edu/bigdata. Screencast at https://www.youtube.com/playlist?list=PLCj1LhGni3hMNhIdrvz1F5-JHIWi1qdX1
PirateBox for Data Literacy

Distributing files via PirateBox
A PirateBox is a wireless router that has been reconfigured to serve as a local fileserver. The PirateBox project develops software to do this. PirateBox makes it easy to share files with anyone within range of the router, and also supports a local anonymous discussion board for those within range.
I did this for the TP-Link TL-MR3040, a commonly used piece of hardware for PirateBoxes. The MR3040 is small and battery powered, so you can easily carry it in your pocket to places that have no electricity or internet. The file system goes on a removable USB, so it is easy to set up by just copying stuff from your computer to the USB.
Configuration is not really that difficult if you follow the instructions here at the PirateBox project site.
To customize your SSID (the name of your wireless device) and Home Page you can follow these instructions.
Workshops hosted on PirateBox
I have used my PirateBox to share workshop slides, articles, and code. Up to down this has been a small supplement to my normal workshops, but it could have a larger role.
What I would like to do is to create a self-contained training environment that would not depend on the vagaries of local configuration and connectivity issues. Following a “train the trainer” model, one could build a PirateBox with an entire data literacy course running off of web pages on the PirateBox. The PirateBox could include all necessary software (a complete R installation, for example) and a collection of supporting documents, datasets, code, and any other information. This material could also be mirrored to/from a regular website, but the portable and self-contained aspect of the PirateBox opens up many possibilities.
So the trainer could walk into a room anywhere in the world (for example a small Mongolian town – сум), with their PirateBox and lead a workshop based on materials that reside in their entirety on the PirateBox. Then leave the PirateBox behind so that those in the community could continue to work with the materials and any additional modules. They could adapt, repurpose, and create their own materials too. So the PirateBox can support ongoing learning, far beyond the limits of one-shot workshops.
These are not especially new ideas, and even as I type people are surely hacking wireless routers and other devices to perform other advanced functions. Doubtless the technology will continue to develop. But for now, the PirateBox software allows one to do interesting work with less than $50 in hardware and a couple of hours in setup time. Who knows? One can dream of hordes of data literacy pirates emerging from this simple technology.
Data Science in Mongolia – Маш их сайн! (very good!)
While it is the subject for another blog post or another blog, Mongol culture has long held my fascination. Thanks to a series of fortunate events, I had the opportunity to bring some of my favorite interests (data, statistics, R, Mongolian) all together to form an unforgettable experience in May 2017. During one week in Ulaanbaatar, I visited three of the oldest, largest, and most important Mongolian universities, as well as the nerve center of Mongolian data, the National Statistics Office.
 National Statistics Office of Mongolia
National Statistics Office of Mongolia
The first and most intensive event was my invitation to present two days of workshops on Data Science at the National Statistics Office of Mongolia (Монгол Улсын Үндэсний статистикийн хороо). On May 8 and May 9, I delivered all-day presentations and interactive training on Data Visualization, Big Data, Reproducible Research, and Data Literacy. The presentation slides in English and accompanying Mongolian translation are available here.
We covered lots of ground, and I was also able to learn about the data environment in Mongolia and some of NSO’s data dissemination efforts such as the 1212.mn data portal. The facilities at NSO were superb, and the audience of 33, consisting primarily of government data professionals from the NSO and other Mongolian agencies were an outstanding group. It was truly a privilege to be able to work with them. An article (in Mongolian) about the event is here.
In particular, I would like to thank Ch. Davaasuren (Research and Development Director of the Mongolian Marketing Consulting Group for arranging the event, to L. Myagmarsuren (Director of Information Technology at NSO) for hosting it, and to A. Ariunzaya (Chair of NSO) for the invitation.
These three can be seen at the opening of the event [at the link below], along with me and my poor Mongolian – уучлаарай (sorry!). I promise it will improve!
NSO Data Science opening remarks
The event was greatly enriched by sponsorship from IASSIST, the International Association for Social Science Information Services and Technology. IASSIST is developing outreach efforts to areas around the world, and provided translation services and lunch for workshop participants. We had two days of delicious хуушуур (huushur), сүүтэй цай (milk tea), and other Mongolian specialties at Modern Nomads. Joining IASSIST is a great way to get in touch with a worldwide network of data professionals!
 National University of Mongolia
National University of Mongolia
On Wednesday, May 9, I spoke on Data Literacy to approximately 70 students of statistics at the National University of Mongolia (Монгол Улсын Их Сургууль). Even though the talk started at 7:40 am, students were attentive and asked probing questions. Clearly, they are the future of data science –very curious about career trends and the nature of the work and skills required. I am sure they will succeed if they remain as focused as they were that day! Амжилт хүсьё!
Thanks to D. Amarjargal for inviting me, and B. Myagmarsuren for translating!
 Mongolian University of Life Sciences
Mongolian University of Life Sciences
On Thursday, May 10, I traveled to the southern side of Ulaanbaatar to speak at the Mongolian University of Life Sciences (Хөдөө Аж Ахуйн Их Сургууль), giving two presentations on Big Data and Data Visualization to a group of approximately 20 faculty of the School of Economics and Business.
The faculty here were very welcoming and discussed many issues in applying big data and visualization techniques to their work. Many thanks to P. Munktuhya (Head of the Department of Economics, Statistics, and Mathematical Modeling) for arranging the event, to G. Ganzorig (Senior Lecturer in Agricultural and Applied Economics) for translation, and to B. Baasansukh (Dean of the School of Economics and Business) for the invitation.
I was also able to have a very informative and positive meeting with Ts. Sukhtulga (Chief of Administration and International Affairs) to discuss possibilities for cooperation with Rutgers University. An article (in Mongolian) about my visit appeared here. I really regretted not having more time to spend here!
![]()
Mongolian University of Science and Technology
My final talk on Friday, May 11 was at the Mongolian University of Science and Technology (Шинжлэх Ухаан, Технологийн Их Сургууль), where I spoke on Big Data, Reproducible Research, and Data Visualization, hitting highlights from my earlier presentations during the week.
Approximately 40 faculty and students from MUST’s School of Business Administration and Humanities attended. Once again, the audience was attentive and questioning up until the end, even though the talk was held late on Friday afternoon. I was very impressed by the curiosity and dedication of the Mongolian academic community here, and throughout my trip.
At MUST, I would like to thank J. Oyuntungalag (Professor of Technology Management) for arranging the talk. I also enjoyed a good meeting with U. Batbaatar and P. Jargaltuya of the Office of International Affairs and Cooperation.
On Friday, I was also able to spend some time at the Mongolian Marketing Consulting Group‘s offices to learn more about how they conduct polling, market research, and other data collection, thanks to the hospitality of Ch. Davaasuren.
It was such a memorable and rewarding experience that I must continue to thank those who made it possible, once again Ch. Davaasuren who helped throughout the week, and especially to M. Bayarmaa who worked tirelessly to organize many aspects of the week’s events and behind the scenes to keep things running smoothly.
I can only hope that this is the start of a long and productive collaboration with the Mongolian data world.
Би цагийг гайхалтай сайхан өнгөрөөсөн! (I had a glorious time!)

Recent Comments